This was shared by a colleague. The discussion centered on how log-structured databases are not designed for a 1:1 read-to-write ratio. There are various ways to tune the data structure to favor one over the other. You can read the original article here .
About Pat: He is a leading author in areas like distributed architecture, database transaction processing, and more. You can find his latest research on his ACM profile page . Blockquotes in this post are excerpts from his article.
I’ll be posting new articles once or twice a week. Subscribe for free to receive updates .
Indexing within a database
Regarding RDBMS and indexing:
relational database and how indexing can optimize access while being transparent to the application. Updating an index meant another two disk accesses since the indices of a B+ tree didn’t fit in memory
The question is: how many indexes? One per column? Every possible pair of columns?
more indexing we did, the faster the read queries would become. The more indexing we did, the more our ability to update became slower than molasses.
These are common tradeoffs. Reading fast frequently means writing slow.
Row-store versus Column-store
It’s natural to associate high-performance updates with ‘row-store’. Another approach is to organize data by columns.
Column-stores allow more efficient access to data when querying a subset of columns, as they avoid reading unnecessary columns.
Columnar databases are super fast for querying because many logical rows with the same value are physically close to each other. Updating the column store is not easy
Updates are kept separately in an integrated row-store.
Typically, updates go to a small row-store, and queries combine results from this and the column-store. Periodically, these updates are merged into the column-store, often using a cascading process like level-based compaction in LSM trees (explained in the next section ).
Insertion in column-store(buffered into row-store really), you are incurring a debt to be paid later. This debt to rewrite and integrate the new data is a form of write amplification where a single write turns into more writes later.
LSM: Log-structured Merge Trees
LSM trees were first proposed in 1996 by O’Neil et al. in this research article , but lacked adoption for years—until Google used them in BigTable .
idea is to track changes to a key-value store as transactions with new values are kept in the memory.
In key-value pair, the value can be multiple field values, JSON, blob, or anything. LSM tree has an in-memory buffer and leveled storage as shown in the image below.
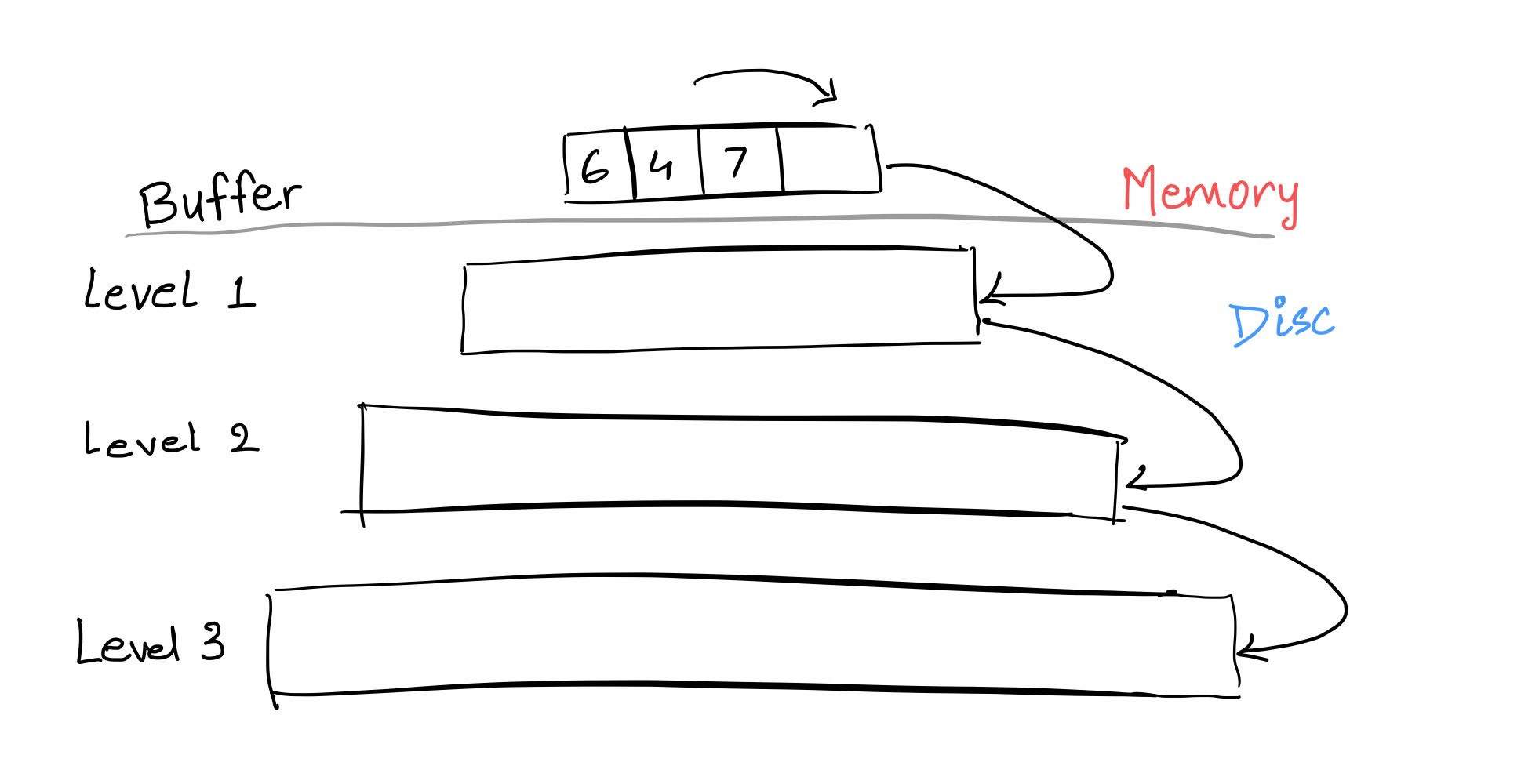
As transaction commit, sorted collection of recent key-value pairs can be written to disk. This file contains the sorted key-value pairs along with an index to the keys in the file. Once written to disk, newly committed changes do not need to be kept in memory
In LSM trees, new data is inserted into an in-memory buffer. When full, this buffer is sorted and flushed to disk as an immutable file—resulting in compact storage and high ingestion throughput, but also read perspiration.
To reduce read perspiration, the Log-structured merge (LSM) tree invests energy to organize the data by rewriting it as you go. To make it easy to find keys, these are merged with files that were written earlier. Each log-structured merge (LSM) tree has some form of fan-out where lower levels of the tree are kept across more files.
Here organizing data means once the buffer is flushed to an immutable file, compaction happens. Compaction is the process to merge two or more sorted immutable files. In the LSM tree, updates are out-of-place (This result in space amplification as duplicate values are getting stored). The update gets inserted as another key-value pair and the previously stored pair is logically invalidated. While merging two files, a previously written key-value pair that is now logically invalidated gets removed.
LSM tree depends on the fan-out, the size of each file, and the number of key-value pairs in the tree. In general, most of the storage is in the lowest level of the tree.
The frequency of compaction and amount of data merged during compaction is the tunable parameter of the LSM tree to solve write amplification or read perspiration.
Leveling merges
When a new file is added to a level, pick the next file in the round-robin traversal and merge it with the files next level below.
If the next level down is grown above the nominal size, it will move one level down and merge with it. This process gets repeated if the level is grown above the nominal size in cascading fashion. By doing this periodically, there will be low space amplification, and reads will be faster
Leveling merges have a large write-amplification. Each write of a new key-value pair to the first level will be written multiple times at each level it moves through. On other hand, they have small read perspiration, as the query typically checks only one place per level.
Tiering merges
different but the related approach, files get to stack up on each level before doing the merge. This dramatically reduces the amount of merging required. Tiering merges have lower write amplification but larger read perspiration. Files are stacked up so less merging and hence less writing.
Reads need to be checked in lot more places leading to larger read perspiration
Indexing and Searching
Seach is in many ways a variety of database indexing. Search systems are a bit different in that they deal with the document. Most search systems asynchronously update the search index after the change to the document occurs.
Search makes reading the documents a lot easier. It dramatically lowers the read perspiration.
Updates to the documents asynchronously impose a debt onto the system to get them indexed. Creating and merging search indices is a complex job which is a form of *write amplification.
To index, you need to scour the corpus to find recently written or updated documents. Each of these needs to have an identifier and then needs to be processed to locate the search terms (n-grams)
Each of these many n-grams found in a typical document then needs to be sent to an indexer that covers one of many shards. So, the document identifier now is associated with each term (or n-gram) located in the searchable document.
All of these because there was an update or creation of the document. write amplification
Internet-scale search systems clearly offer excellent and low read perspiration.
Large-scale Caches
Lots of big Internet systems have ginormous caches. Whenever anything changes, lots of servers are updated. This makes for a very easy and fast read in exchange for larger write amplification.
There will be a different article in the future for the large-scale caches. I’ll be covering research articles published by Meta (Facebook) and Twitter. I will be posting new articles on my website. Subscribe for free to receive new post updates .
Normalization and Denormalization
Working to avoid update anomalies was deemed to be extremely important. Performing a large number of joins to get an answer was a small penalty to pay to ensure the database wasn’t damaged by an errant update.
Most systems are getting more and more distributed. Most of these have key-value pairs containing their data, which is sharded for scale.
If you were to normalize the data in this big and sharded system, the normalized values would not be on the same shard together. Doing a distributed join is more annoying than doing a centralized join.
To cope with this, people superimpose versioning on their data. It’s not perfect but it’s less challenging than distributed joins or trying to do massive updates across the denormalized data.
Large-scale distributed systems put a lot of pressure on the semantics of a consistent read. This, in turn, can be seen as a tension between write amplification and read perspiration.
Conclusion
We’ve looked at just a few of the examples where there are tradeoffs in our systems between write and read. We see emerging systems that adapt and optimize for these tradeoffs as they watch their usage patterns.
This article provides a snapshot of how distributed systems balance data structure design, indexing, compaction, and cache invalidation in the context of real-world workloads. Subscribe for free to receive new post updates .