There are a lot of articles about Apache Kafka[1] regarding how companies are using it, what kind of problems Apache Kafka solves, how to create producers and consumers etc. Instead of directly jumping on those (will explore those in the future posts for sure though), let’s look at why it was built and why it’s faster than other messaging solutions.
What is Log?
The very first line of the Kafka paper[2] says
Log processing has become a critical component of the data pipeline for consumer internet companies
What is log data here that they are talking about? The first thing it came to mind was application logs which kinda look like this,
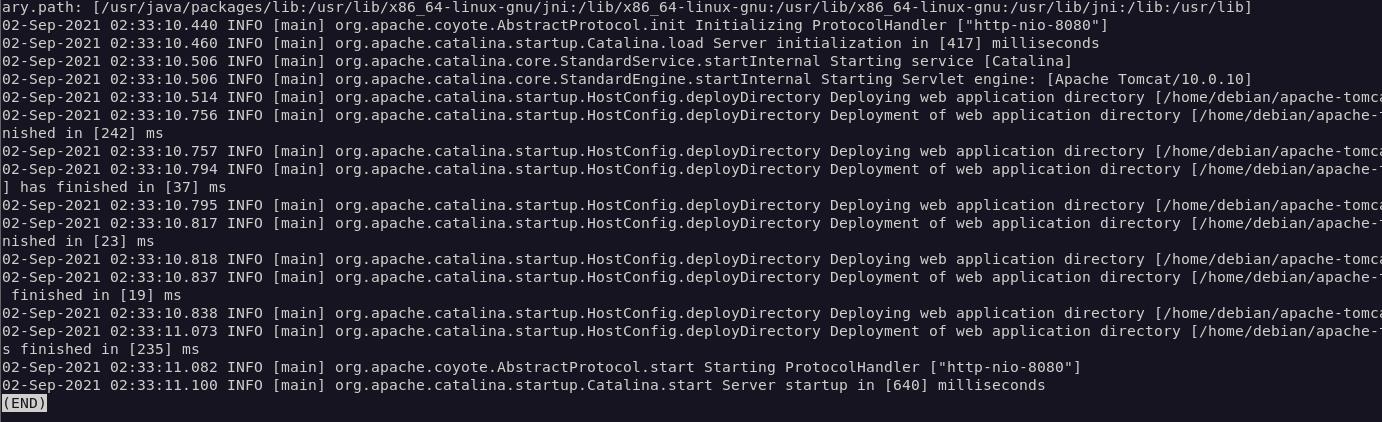
These Tomcat logs are humanly readable which simplest form of log that they are talking about which software produces.
Log is a chronological record of actions/performance generated by system or human.
Here, the system can be a simple web server, operating system, or software that generates syslogs[3], most database systems have transaction logs, etc. The system puts these logs into a single log file which we know as Logging. Some logs might be human-readable text files or some can be binary which the Database system provides.
Transaction logs that are generated by the database is a chronological history of record of change made to the database. Those are separated from actual data files. In the MySQL world, it is known as ‘Binary Log’ and in Postgres, it is known as ‘Write-Ahead Log (WAL)’.
The logs here might be called ‘commit log’ or ‘journal’. From Jay Kreps’s blog on LinkedIn Engineering[4], Log is append-only, chronologically ordered records. Newer entries are added at end of the log.
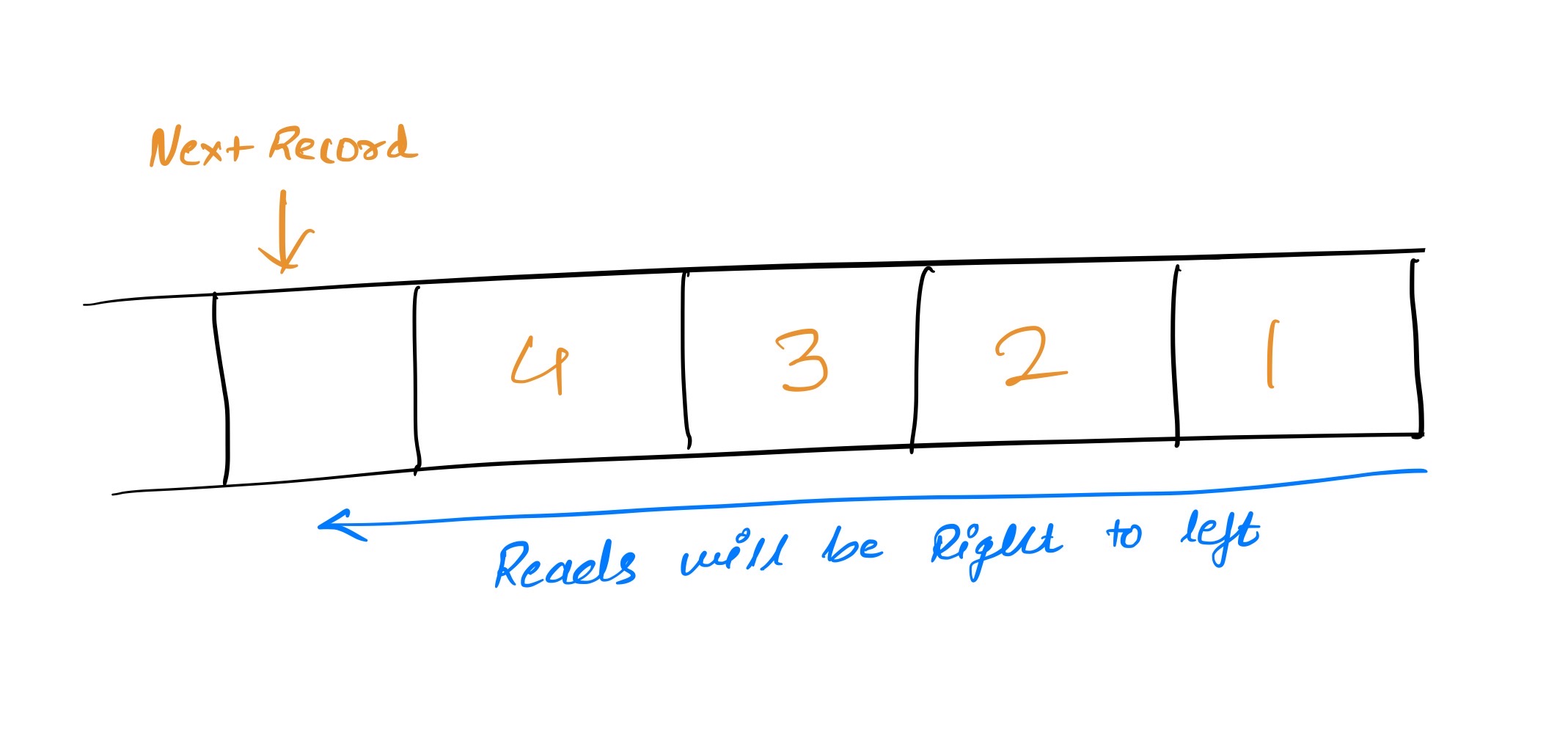
Log entries are pushed behind one another and reads proceed from right to left. Each record has been assigned a unique sequential log number. These are chronologically ordered, entries to the left record are older than their right side ones and the log number can be thought of as a timestamp. By describing ordering as a notion of time, Log entries are decoupled from the physical clocks. This is an essential property in distributed systems.[4]
There won’t be a single file where entries are recorded, the file will get too large or will run out of space. We’ll look into that in a future post.
Every software engineer/programmer is familiar with one or another definition of logging. We have seen one of the examples of the tomcat server above, the front-end developer using console.log() to write messages to the browser console. This are “Application logging” - unstructured error messages or trace info[4].
Logs in Database
We’ll look into Logs in Databases. Now and then server crashes, it might be a power failure at the data center or it might be a software issue. Stating Murphy’s law, ‘Anything that can go wrong will go wrong’ and it’s extended to ‘Anything that can go wrong will go wrong, and at the worst possible time’. The goal for the product should be to have minimum disruption if any of the services faulted.
Therefore, Database systems that have durability, ensure changes made to the database that are successfully committed, will survive, in case of disruption. These are achieved by a commit log in the database system. Databases use the log to write information about these changes made to records before those changes are applied to the various data structure that DB maintains. Since the log is persisted instantly, it is used as an authoritative source to restore other persistent structures in event of failure.
As time went on, internet traffic increased, and having one database server to handle writes and reads impacted as well as availability. Having another database server or multiple servers that cater read operations, increases availability significantly. There are a lot of strategies are being used to replicate databases for read replicas or cross geo-replication. We will take the example of asynchronous replication, which is the most common and out-of-box configuration for many distributed systems.
In asynchronous replication, once the write operation completes, it immediately responds to the client. After that databases send the write operation’s transaction log to remote replicas to be in sync. Most databases have these kinds of log shipping protocols packaged which sends portions of the log to remote replicas.
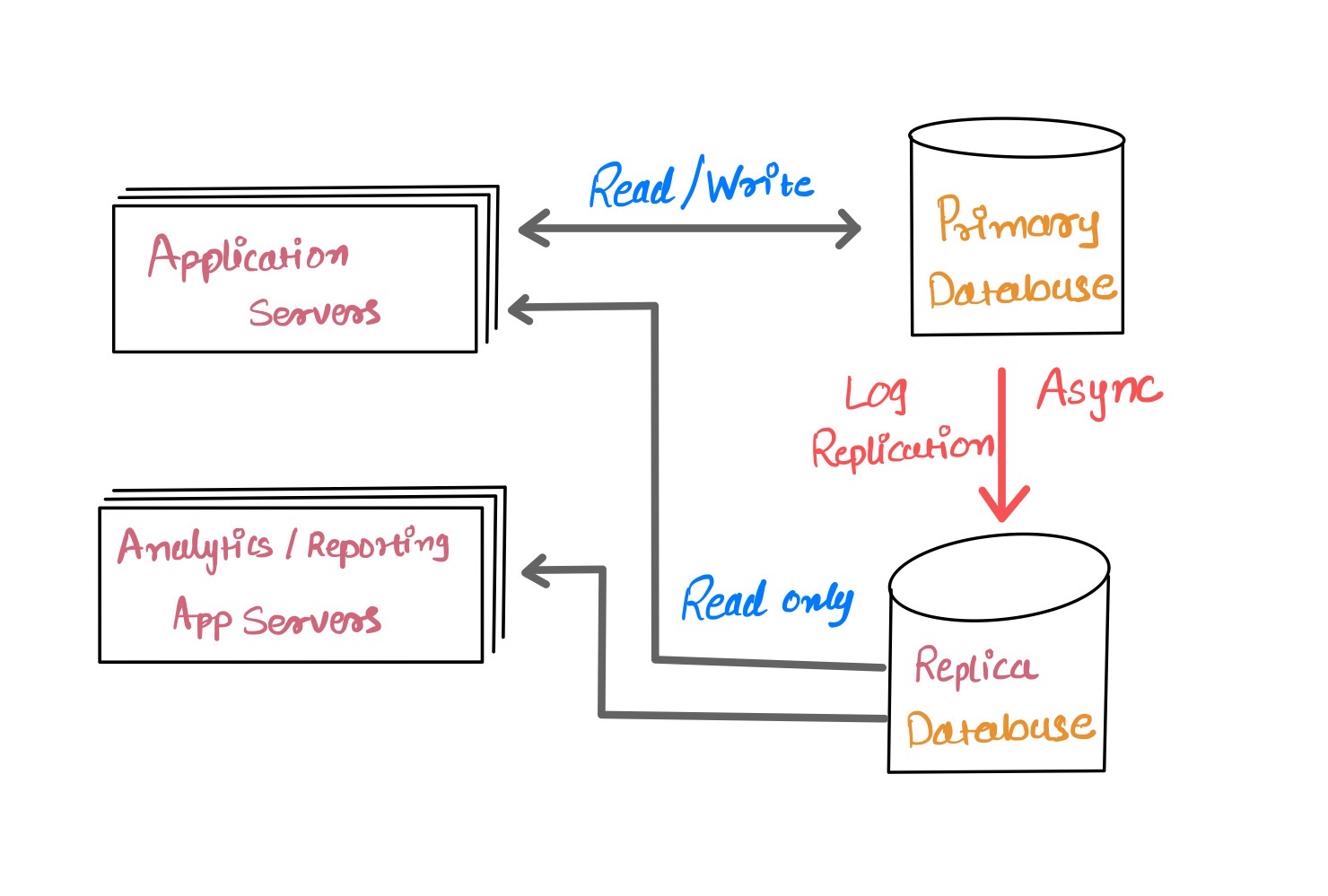
The mechanism of using a transaction log for data transmission or processing is very much ideal for various data integrations or real-time messaging.
Logs in Distributed System
Will be added soon.
Next
My next post will be on comparison of other messaging queues like RabbitMQ, JMS etc. with Kafka.
Checkout Messaging Queues - Apache Kafka Series - Part II
Bibliography
- Apache Kafka, https://kafka.apache.org
- Jay Kreps, Neha Narkhede, and Jun Rao: “Kafka: A Distributed Messaging System for Log Processing”, at 6th International Workshop on Networking Meets Databases (NetDB), June 2011.
- Syslog Link
- The Log: What every software engineer should know about real-time data’s unifying abstraction by Jay Kreps Link